

Рынок распознавания эмоций оценивается в $20-30 млрд, только пока вендоры не знают, как к нему подступиться
Всплеск публичного и научного интереса к теме детекции и распознавания эмоций, а также бум опирающихся на эти данные технологических решений пришлись на вторую половину 2000 — начало 2010-х годов, пиковых значений эти процессы достигли к рубежу 2015-2016 годов. Тогда сразу два технологических гиганта — корпорации Microsoft и Google — сделали доступными для обычных пользователей свои пилотные проекты. Демоверсия программы Microsoft (Project Oxford), например, быстро стала популярной игрушкой. Идея состоит в том, что вы загружаете онлайн фотографию, а программа пытается с какой-то степенью вероятности детектировать эмоцию по микроэкспрессиям лица, выбирая из шести базовых: презрение, отвращение, страх, счастье, грусть, удивление или фиксируя нейтральное состояние.
Еще один глобальный игрок — корпорация Apple — приобрела стартап Emotient, у истоков которого стоял один из первопроходцев и наиболее известных популяризаторов науки об эмоциях Пол Экман. При этом часто на рынке появлялись интересные продукты от небольших компаний, уже заявившие о себе на рынке. Например, Аффектива (Affectiva), которая выросла из стен лаборатории эмоциональных вычислений (affective computing) Массачусетского технологического института. Еще в 2013-м в американском Forbes называли продукт Affectiva одной из пяти самых прорывных технологий. Похожий проект — Emotient — делают выпускники калифорнийского института в Сан-Диего, а инвестор у них — Intel.
За прошедшее время алгоритмы стали лучше, но по-прежнему актуален вопрос о практической пользе технологий. Как применить тегирование эмоций друзей на фотографии в Facebook или трансформацию улыбки в персонализированный смайлик-эмодзи? Можно довольно успешно использовать такие технологии в нейромаркетинговых целях. Например, та же Affectiva позиционирует один из своих продуктов сугубо для проведения маркетинговых исследований. Однако есть значимая проблема. Все эти продукты, будь то платформенные или облачные, как правило, детектируют эмоции человека по мимике на его лице. Грубо говоря, выбирается определенное количество точек на лице и сравнивается с банком фотографий, на которых эмоция уже распознана. Однако этого недостаточно.
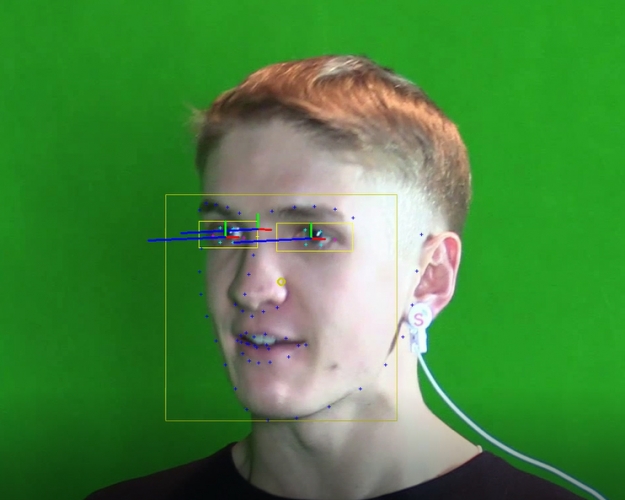
Многоканальные эмоции
Если смотреть видео без звука, то можно четко считать одну конкретную эмоцию. Едва включаешь звук, картина может измениться: восприятие эмоции будет уже совсем иным. Один канал информации задает достаточно жесткие ограничения и до тех пор, пока программа для распознавания эмоций остается больше в статусе «игрушки», ошибки не так критичны. Если же мы претендуем на результат максимально близкий к 100% и хотим сделать бесконтактный детектор эмоций, поведенческих паттернов и физиологических реакций организма, то нам нужны дополнительные источники информации о впечатлениях человека. Та же ложь — это отчасти сокрытие эмоций. И если мы поймем, какие именно эмоции пытается спрятать от глаз собеседника или объектива камеры человек, тогда сумеем выявить, когда он прямо врет, уходит от ответа или же что-то недоговаривает. Представьте себе топ-менеджера или политика, выступающего на пресс-конференции. Он может декламировать с трибуны с абсолютно каменным лицом, но интонации голоса, движения его глаз или тела почти наверняка в какой-то момент выдадут его.
Для корректного распознавания эмоций требуется гораздо больше каналов, во всяком случае не менее четырех, анализируемых синхронно. Первый — собственно, лицо человека. Мимика распознается достаточно четко — регулярно проходят международные соревнования и хакатоны, где сборные команды из разных стран показывают свои решения. Обычно строится 3D-модель головы, и на ней отлавливаются микродвижения мышц. Второй канал — глазодвигательная активность. Отслеживание движений глаз, саккад и фиксаций, дает очень много важной информации, ведь визуальное восприятие действительности — в каком-то смысле главное для человека. Третий — движения тела, включая мелкую моторику, едва заметную невооруженным взглядом: руки, пальцы, колени, ступни и так далее. Ну а четвертый канал — голос. И здесь тоже колоссальное поле для работы: ведь можно не только распознавать интонацию, но и вычленять эмоциональную окраску речи, смотреть, что и как говорит человек.
На самом деле существуют и другие каналы, в частности физиология. Например, ускорив видеозапись и отследив колебания головы, можно измерить пульс. И установить, учащается ли он в какой-то ситуации или нет. Выражения «тень пробежала по лицу» или «лицо побелело от ужаса» воплощаются в реальности — это можно увидеть на видеозаписи, но она должна быть идеального качества. Уже сейчас имеются примеры технологий, отслеживающих изменение цвета пикселей на лице человека — так можно понять, как сосуды наполняются кровью. Такие эксперименты еще в 2012 году делали ученые из MIT, и на своем демовидео они показали, как можно измерять пульс, например, у спящего ребенка. Но пока это единичные случаи, и широкого применения такие технологии не получили.
Примеров не хватает
Использование дополнительных каналов ведет к неизбежным трудностям — резко возрастает вариативность. Но это расплата за точность распознавания эмоции. Решить эту проблему можно с помощью глубокого обучения нейросетей, направления, которое развивается сравнительно недавно, но уже позволило индустрии по распознаванию эмоций подняться на принципиально иной уровень. Дальше казалось бы все просто: нейросеть берет картинку в реальном времени и сравнивает ее с огромной базой эталонных видео, где искомые эмоции найдены и известны. И алгоритм справляется с задачей на хорошем уровне. Но тут следует учесть одно обстоятельство: подобных датасетов (наборов) мало, а по ряду каналов они порой не существуют вовсе. Создать большой датасет дорого и трудоемко, поэтому в сети даже попадаются научные работы на тему работы с маленькими датасетами — получения максимум выгоды из маленького набора.
Для распознавания эмоций по изображениям нужен массив фотографий, для распознавания эмоций по видео — соответственно, набор видеороликов. Таких состоятельных с научной точки зрения датасетов в нашем распоряжении не так уж и много, поэтому специалисты нередко вынуждены оперировать одними и теми же выборками, параллельно пополняя их и двигая тем самым вперед всю отрасль. Создание датасета — процесс трудоемкий, требующий значительных ресурсов. Во-первых, необходимо продумать сценарии для актеров или других вовлеченных лиц, чтобы в диалоге с экспериментатором они испытывали, а значит так или иначе выражали различный спектр эмоций. И чем ближе условия коммуникации к естественным, повседневным, тем лучше.
В ходе беседы эмоции сменяют друг друга или даже смешиваются, добавляются различные оттенки. Переход может быть резким или плавным, меняется интенсивность экспрессии и иные параметры. После того, как материал отснят, с ним начинает работать аннотатор — специалист, вручную размечающий присутствующие на записи эмоции. Сколько аннотаторов нужно привлечь для получения качественной разметки? Одного-двух? На самом деле не менее десяти. Причем многое зависит от того, каким образом аннотатор размечает эмоции. Он может просто указывать временной промежуток отдельной эмоции или же отмечать ее интенсивность. Помимо общепризнанных базовых эмоций, с которыми все более-менее ясно, требуется дополнительный классификатор, охватывающий промежуточные эмоции и их сочетания. Еще один аспект — голос. Когда усиливается эмоциональность общения, люди нередко перебивают друг друга, перехватывают очередность реплик или же говорят одновременно, а то и внахлест. Распознавать голос в этом случае сложнее — по сути, надо разделить две-три аудиодорожки и вычленить нужную, а уже потом работать с ней. Этот фактор, к слову, надо учитывать и при составлении сценариев съемки.

Итак, лаборатория записала датасет, аннотаторы его разметили, нейросеть научилась работать с ним. Все готово? К сожалению, не совсем. Классификаторы приходится порой переучивать, а то и обучать заново, принимая во внимание этнокультурные и языковые особенности. Впрочем, в современном мире многие вещи универсализируются, сглаживаются, хотя и не до конца. Например, индиец, выросший в США, будет выражать эмоции схожим с коренными американцами способом, но могут быть и нюансы. Люди неизбежно адаптируются к среде, перенимают жесты, манеры, способы, правила и нормы выражения эмоций. И они, разумеется, порой зримо отличаются. Попробуйте понаблюдать со стороны за деловыми переговорами американцев с китайцами, и вы получите ценнейший материал для сравнительного анализа
Объем рынка
Создание системы, которая приблизится к человеческому уровню распознавания эмоций, — это амбициозная цель и захватывающе интересный процесс. Что стоит на кону? Среди лидеров индустрии наиболее заметны корпорации, — например, Google и Facebook — зарабатывающие на данных о поведении человека во всемирной сети. Они обладают максимально полной информацией о том, на какие сайты мы заходим, в каких местах бываем, что нам нравится или нет, каков наш круг общения. Все это конвертируется в таргетированную, «умную» рекламу. Но с каждым годом объемы данных растут. Рано или поздно мы сможем узнавать человека по походке, отслеживать уровень его стресса, досконально понимать его эмоции. Системы детекции и распознавания эмоций, эмоциональные вычисления, востребованы во многих отраслях — от робототехники до биометрии, от цифровой медицины до интеллектуального транспорта, от интернета вещей до игровой индустрии, не говоря уже об образовании и AR/VR.
Сегодня в гонку вовлечены как гиганты рынка, так и стартапы, они и конкурируют, и органично дополняют друг друга. Вместе с тем эмоциональные технологии на базе нейросетей и машинного обучения — все еще молодое направление (new emerging market, по мнению большинства аналитиков), и, как ни крути, все подобные проекты экспериментальны.
Оценки объемов рынка распознаваний эмоций разнятся. Относительно систематизированные отчеты выпущены фактически только на рубеже 2016-2017 гг. Например, Markets&Markets считают, что объем рынка детекции эмоций вырастет с $6,72 млрд в 2016 году до $36,07 млрд к 2021 году, а годовой темп роста составит 39,9%. А по оценкам Orbis Research глобальный рынок распознавания эмоций в 2016 году оценивался в $6,3 млрд, и к 2022 году достигнет $19,96 млрд.
Задачи на будущее
Проблемой распознавания эмоций компании занимаются уже давно. Какие сейчас есть вызовы в этой сфере? Бум искусственного интеллекта (AI) и машинного обучения, который начался буквально пару лет назад, пришел и сюда. Все крупные игроки пытаются научиться применять AI и при распознавании эмоций. Например, в январе 2017-го Google заявила, что планирует встраивать распознавание лиц и эмоций на основе AI в «умные» платы для робототехники Raspberry Pi. Недавно Microsoft объявила, что научила искусственный интеллект распознавать эмоциональную окраску текста.
Машинное обучение потенциально способно решить проблему, но требует большие выборки для обучения, а они не всегда в наличии, поэтому надо придумывать новые способы получения «сырья» для обучения системы. К тому же в Affectiva правильно утверждают, что с применением машинного обучения возрастают затраты. И надо придумывать, как их снижать, но при этом не терять в точности распознавания.
Однако, главный вызов для ученых и разработчиков сейчас — суметь увязать все элементы системы в единое целое.
