

Принимая во внимание важность (порой критическую) охраняемых данных, пока говорить о полной замене человеческого интеллекта искусственным рано
«Мы должны быть очень осторожны с AI (artificial intellegence, искусственный интеллект)», — твитнул Elon Musk пару лет назад, а затем создал Open.AI, некоммерческую исследовательскую организацию, ставящую себе целью распространение знаний об искусственном интеллекте. AI — это будущее, которое стремительно наступает, а в каких-то областях прочно проникло в нашу повседневную жизнь. Автономные автомобили, синхронный real-time перевод с иностранных языков в Skype и рекомендации в музыкальных сервисах наподобие Apple Music — все это стало возможным благодаря AI.
При этом существует путаница между понятиями artificial intelligence (AI), machine learning (ML) и deep learning (DL). Смешение понятий подогревается шумихой, создаваемой СМИ. А она порой мешает пониманию базовых принципов и идей, лежащих в основе любого AI-driven-продукта, и не дает отличить простой маркетинг от сложной технологии. К примеру, после того как алгоритм Alpha Go компании Deep Mind, приобретенной Google за $500 млн, несколько раз обыграл Ли Седоля, чемпиона мира по игре в го, многие популярные издания смешивали данные понятия.
Разберемся, как же соотносятся между собой AI, ML и DL.
AI, или искусственный интеллект (ИИ), — раздел науки, довольно широкий термин, применимый к любой технике, позволяющей программам мимикрировать «человеческий интеллект», выполняя творческие задачи/функции, которые традиционно считаются прерогативой человека, такие как, например, принятие решений или поиск закономерностей.
ML, или машинное обучение, — обширный подраздел ИИ, математическая дисциплина, в которую включают такие области как статистика, методы оптимизации и теория вероятности. По сути, машинным обучением можно назвать определенный набор техник и алгоритмов, с помощью которых решаются те или иные «когнитивные» задачи, например, распознавание речи или рукописных цифр. При этом, говоря о машинном обучении, мы имеем в виду лишь решение какой-либо узкой задачи, а не создание искусственного Интеллекта с большой буквы И — обладающего сравнимыми с человеческими возможностями и способного создавать произведения искусства и поддерживать живую беседу с человеком.
В свою очередь, DL — один из видов ML, в котором используются алгоритмы особого вида — нейронные сети, которые являются, на самом деле, последовательностью довольно простых математических преобразований. Путем наслоения этих преобразований друг на друга (отсюда понятие «многослойные нейронные сети») можно получить очень сложные, нелинейные зависимости, и подстраивая параметры этих преобразований, решать ту или иную задачу, например, задачи машинного зрения- распознавание лиц или других объектов на фото и видео.
В целом взаимосвязь между AI, ML и DL можно хорошо показать с помощью концентрический окружностей.
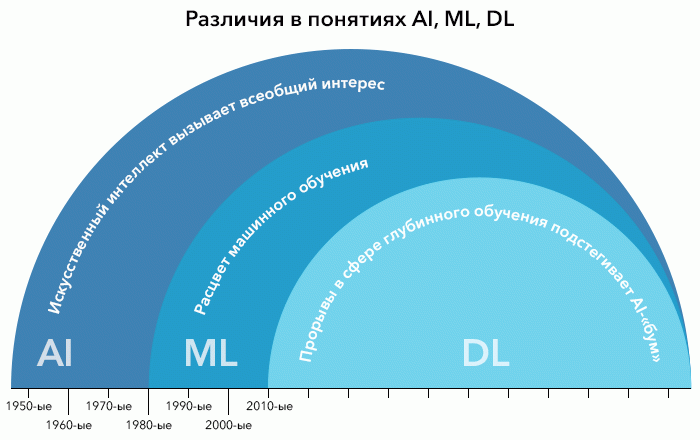
Cтоит обозначить понятия «обучения с учителем» (supervised learning) и «обучения без учителя» (unsupervised learning), которые понадобятся нам далее, для понимания принципов работы ИИ-решений.
Supervised learning — модель, когда система учится на предварительно «размеченных» данных. Например, задача предсказания стоимости автомобиля при известных исторических данных (тех, на которых система «обучается») о стоимости и ряде признаков (также называются features) в обучающей выборке (задача регрессии) или задача классификации — определить, болен человек или здоров, опять же, по историческим данным и ряду признаков, соответствовавших тому или иному случаю.
Unsupervised learning — модель, при которой данные не «размечаются», а сразу, в сыром виде загружаются в систему, которая затем структурирует их. То есть, системе ставится следующая задача: «вот данные — найди в них взаимосвязи».
Заканчивая описание технических подробностей стоит отметить, что AI — горячая тема не только для СМИ, но и для инвесторов.
Инвестиции в AI
2016 год был рекордным для AI-стартапов с точки зрения привлеченных инвестиций — объем сделок составил более $5 млрд., а количество сделок превысило 650.
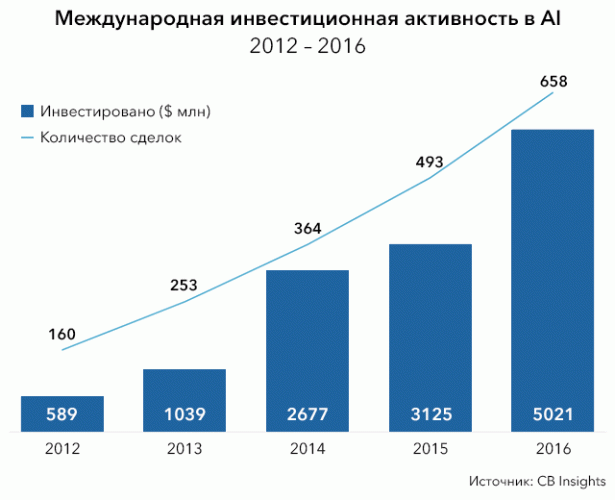
Также в 2016 году было несколько так называемых «мега-раундов» (объемом $100 млн и более). Так, разработчик автономных автомобилей, компания Zoox привлекла Series A раунд в размере $200 млн, Zymergen, стартап в области биоинформатики, привлек Series B раунд в размере $130 млн, разработчики решений в области машинного зрения, SenseTime и Face++ привлекли $120 млн и $100 млн соответственно, а израильский стартап Voyager Labs, разрабатывающий платформу для анализа больших массивов данных, привлек раунд финансирования в размере $100 млн.
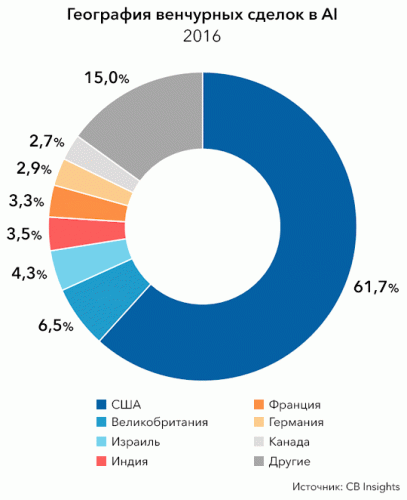
Если говорить о географии сделок, то 62% от общего числа сделок пришлись на стартапы из США, 6,5% — на компании из Великобритании, 4,3% и 3,5% на стартапы из Израиля и Индии соответственно.
Интерес к кибербезопасности возрастает
Кибербезопасность — ахиллесова пята современного мира. Например, Инга Бил, CEO страховой компании Lloyd’s оценивает, что кибератаки и их последствия стоят крупным компаниям $400 млрд. в год, а по оценкам аналитиков, рынок cybersecurity ожидает экспоненциальный рост от $75 млрд. в 2015 году к $170 млрд. в 2020. Также остро стоит проблема нехватки специалистов в области кибербезопасности — согласно данным Bureau of Labor Statistics (США), 209 00 позиций в этой области остаются незакрытым, в то время как количество вакансий выросло на 74% за последние 5 лет.
С другой стороны, крупные технологические компании все больше заинтересованы в security стартапах. Так, в январе Amazon Web Services (подразделение компании Amazon) купил за $19 млн. стартап из Сан-Диего под названием Harvest.ai, разрабатывавший систему MACIE Analytics — решение для защиты интеллектуальной собственности, нацеленное на крупных корпоративных игроков.
Домен .ai говорит нам о том, что в ядре решения, купленного Amazon, находятся алгоритмы машинного обучения — действительно ли машинное обучение является следующим шагом в кибербезопасности или это шумиха, раздуваемая самими компаниями и СМИ?
Security + AI = ?
Если говорить об общей классификации методов защиты от кибератак, то их можно разделить, в зависимости от части сети, которая защищается. Например: защита конечных устройств (endpoint security), защита «облаков» (cloud security) или защита всей сети в целом (network security). Также, отдельно можно выделить защиту в Web, т.е. защиту сайтов, антифишинговое ПО и т.д.
Однако, в целях демонстрации основных принципов применения машинного обучения для решения задач кибербезопасности, приведем классификацию более высокого уровня. Сегодня, системы кибербезопасности можно разделить на 2 класса: экспертные (analyst-driven) и автоматические (machine-driven).
Экспертные системы разрабатываются и управляются людьми — экспертами по кибербезопасности, а принцип их работы основан на распознавании threat signatures (сигнатуры угроз) для предотвращения атак. По существу, threat signatures — это примеры вредоносного кода или техник, которые используются для идентификации и предотвращения кибератак — также, как база отпечатков пальцев используется для поимки преступников. Однако, стоит заметить, что threat signatures распознают и заносят в «базу» только после того, как атака была совершена — в целях предотвращения таких же атак в будущем. Таким образом, подобные системы не способны защитить от ранее неизвестных атак, называемых zero day attacks.
Таким образом работают классические антивирусы от всем известных производителей (в том числе и отечественных), установленные на наших с вами ПК и именно поэтому необходимо регулярно продлевать подписку и обновлять «базы вирусов» — в противном случае ваша система оказывается незащищенной от атак, которые не были занесены в предыдущую версию базы.
Необходимо отметить, что методы и способы атак эволюционируют с каждым годом: так, по данным отчета Internet Security Report компании Symantec количество zero day attacks с 2014 года увеличилось на 125%. Это ставит вопрос: а будут ли в долгосрочной перспективе эффективны signature-driven систем, о которых мы говорили выше?
В свою очередь, автоматические системы используют алгоритмы машинного обучения для предотвращения угроз. Под словом предотвращение можно понимать следующее: ПО идентифицирует потенциально вредоносные или опасные действия в системе или сети, основываясь на анализе исторических данных — то есть, решается типичная задача классификации — одна из базовых проблем машинного обучения.
Таким образом, machine-driven системы, благодаря тому, что действуют «на опережение», позволяют успешно бороться с zero day attacks. В качестве примера таких систем можно привести продукты компании Cylance — единорога, привлекшего суммарно $177 млн.
Однако, и у machine-driven систем есть свои недостатки. По словам Эльдара Заитова, эксперта по компьютерной безопасности Яндекса, в настоящее время, security компании, применяющие алгоритмы ML, используют, в основном, метод выявления аномалий (нестандартного поведения). Это означает, что активность в системе или сети не обязательно должна быть в явном виде вредоносной, чтобы быть отмеченной защитным ПО. Если эта активность соотносится c каким-либо историческим прецедентом, она будет отмечена как потенциально опасная.
Это подводит нас к недостатку существующих machine-driven систем — лишь малая часть из отмеченных аномалий действительно является опасными для системы или сети. Поэтому, таким системам необходима постоянная обратная связь от человека — эксперта по кибербезопасности — который повторно маркирует полученные результаты, отделяя действительно опасные активности от «аномальных».
Давайте разберемся, почему на текущий момент это так. Данные, на которых обучается ML-система определяет ее качество. Здесь и заключается главная проблема для разработчиков security стартапов — большинство крупных компаний не стремится отдавать данные о своих внутренних ИТ-процессах сторонним разработчикам, а тем более — небольшим стартапам. И это понятно — например, крупный банк, несущий ответственность за миллиарды долларов своих вкладчиков, вряд ли захочет с кем бы то ни было делиться конфиденциальной информацией о своей среде.
Симбиоз машины и человека
Так, исследователи из Computer Science and Artificial Intelligence Laboratory в MIT в сотрудничестве с machine-learning стартапом PatternEx (привлекла $7,8 млн. от одного из top-tier фонда Долины — Khosla Ventures) разработали систему кибербезопасности под названием Dubbed AI, совмещающую analyst-driven решения старого образца и методы выявления аномалий, для имплементации которых используется машинное обучение.
Принцип работы следующий: сначала, при помощи метода выявления аномалий, система самостоятельно, без участия человека, обнаруживает всю подозрительную активность — то есть, реализуется схема unsupervised learning. Затем, после завершения предварительной фильтрации, система представляет результаты анализа эксперту, который вручную отмечает все вредоносные активности. После этого, в модель загружаются данные, размеченные экспертом (supervised learning), на основе которых система обучается.
Таким образом, создается непрерывный цикл обучения модели, которая становится более и более точной с каждой последующей итерацией такого цикла.
Однако, несмотря на всю привлекательность данной идеи, коммерческие перспективы подобных систем, на данный момент, встречают высокий барьер в виде опасения крупных компаний отдавать собственные строго конфиденциальные данные сторонним аналитикам.
Подводя итог, несмотря на всю привлекательность идеи автоматический систем кибербезопасности, коммерческие перспективы подобных систем, на данный момент, встречают высокий барьер в виде опасения крупных компаний отдавать собственные конфиденциальные данные сторонним разработчикам. А без большого количества исходных, обучающих систему данных, просто невозможно достичь достаточного для высокого уровня выявления угроз. По словам Эльдара — «серебряной пули нет — ML должно быть одним из множества компонентов, и всё работает только в комплексе».
Также, значительная доля шумихи по поводу AI в кибербезопасности — отличная работа маркетологов компаний. Так, цитируя высказывание Джорджа Курца, в прошлом CTO компании McAfee, одного из крупнейших разработчиков антивирусного ПО, а ныне — CEO CrowdStrike, еще одного единорога в области кибербезопасности, об алгоритмах машинного обучения, применяемых Cylance: «Успехи Cylance, во многом, это заслуга отделам маркетинга. «Алгоритмы машинного обучения», о которых они говорят, давно применяются в McAfee».
Более того, иногда не совсем очевидно, какие же системы работают лучше: классические (экспертные) или автоматические. Так, в середине прошлого года, на страницах блог-постов состоялась перепалка между уже упоминавшейся компанией Cylance и другим известным вендором — Sophos, использующим классические методы обнаружение угроз. Суть перепалки состояла в следующем: Sophos обвиняли Cylance в том, что во время публичных сравнительных тестов эффективности систем на одной из конференций, представители Cylance отключили часть функционала системы Sophos, чем и обеспечили победу своего решения. Затем вышел следующий пост, в котором говорилось о независимых тестах, проведенных неким реселлером, в которых Sophos показали лучший результат, однако, видео не было опубликовано, так как реселлер опасался давления со стороны Cylance. Словом, вопрос о технологическом превосходстве автоматический систем, на текущем уровне их развития, остается открытым.
Если же говорит о прогнозах, то, безусловно, в долгосрочной перспективе, системы кибербезопасности будут все более и более автоматизированными, однако, принимая во внимание важность (порой, критическую) охраняемых данных или объектов, едва ли можно говорит о полной автоматизации и замене человека искусственным интеллектом. На данный момент не приходится сомневаться, что AI в кибербезопасности — это hype и существенная работа отдела маркетинга компаний в связке со СМИ, а системы, использующие машинное обучение, пока что не способны заменить людей-экспертов.
